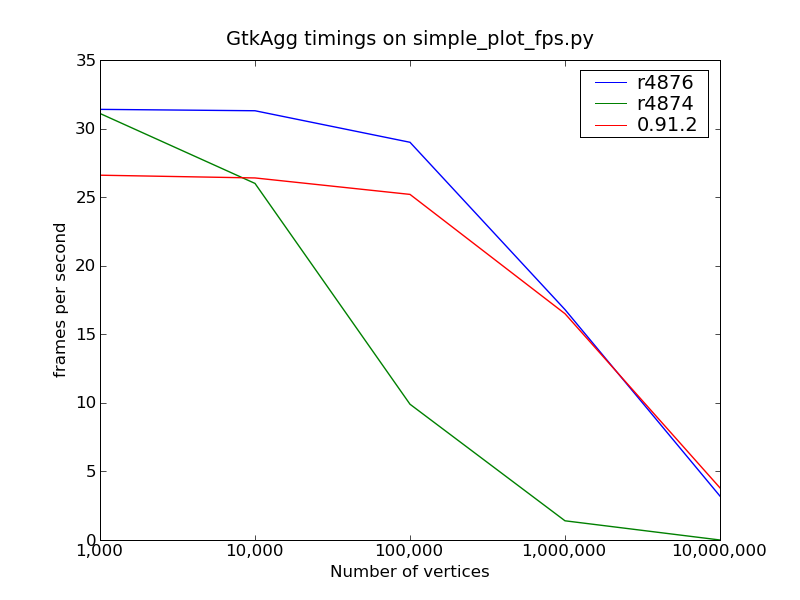
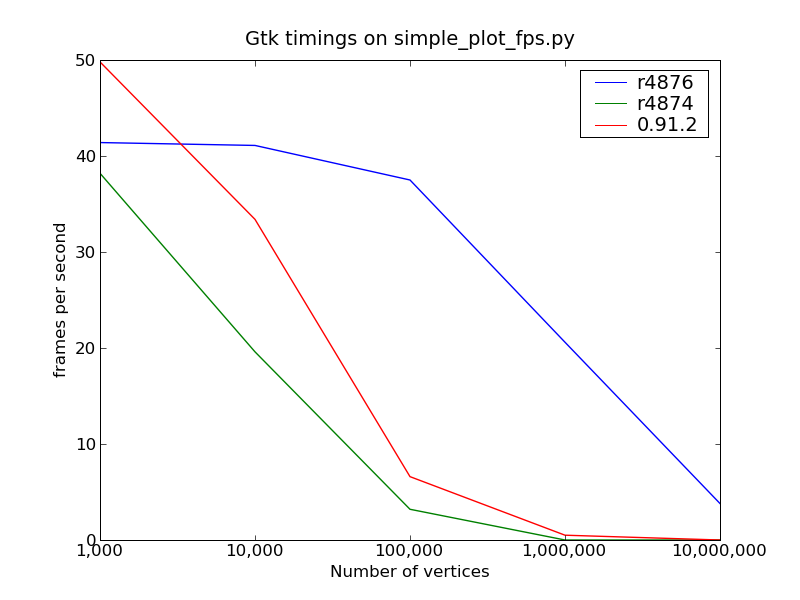
Quick status update, and moving to matplotlib-devel, since I think this is no longer relevant to the OP --
The difference seems to be due to the simplification/clipping/decimation loop in the old draw_lines. It appears that even when you have a sine wave line plotted with 100,000 points, only 75 of them actually end up being sent to Agg. Valgrind's callgrind tells me that most of the time spent on the trunk when you have many line segments is spent stroking the line. So, clearly, drastically reducing the number of line segments should help immensely.
When I made the conversion from draw_lines to everything using draw_path, I had skipped over the simplification step because a) the problem is a little harder with general polycurves (since you can't stop in the middle of a curve) and b) I had assumed, with no evidence, that Agg would be doing some of this anyway.
So, I'm in the process of porting the big loop in draw_lines over to the trunk. It's complicated by curve problem and the desire to avoid a copy, of course, but it should be doable. There's probably a cross-over point at which the time spent simplifying the line becomes less than the time spent stroking the line. That will probably have to be arrived at by experimentation.
Cheers,
Mike
Michael Droettboom wrote:
···
John Hunter wrote:
On Jan 15, 2008 7:46 AM, Michael Droettboom <mdroe@...31...> wrote:
Ah -- just thought of something else.
If I adjust simple_plot_fps.py to have 100,000 data points rather than
1,000 I see something that starts to match with what you're seeing:
GtkAgg:
wallclock: 4.23297405243
user: 3.33
fps: 23.6240522057
Gtk:
wallclock: 15.0203828812
user: 14.92
fps: 6.65761990165
TkAgg:
wallclock: 4.8252530098
user: 4.67
fps: 20.7243018754
You can see that the Gtk time is starting to explode. If I go to
1,000,000 points, Gtk runs out of memory before the first plot, whereas
the other two continue to chug along at a reasonable pace.
From looking at the code, I suspect the crucial difference is that the
Gdk backend uses the Python sequence API (rather slow) to access the
data as it gets rendered, whereas GtkAgg uses the numpy array interface
which is essentially raw access to a C array.
This is not likely to be the culprit -- for drawing markers, the old
matplotlib API made a separate call to draw_polygon for every marker,
with a new gc each time. Many moons ago, we implemented draw_markers
as a renderer method to avoid this problem. For hundreds of thousands
of markers, we saw performance benefits of 25x to 100x. The backends
which implement draw_markers (Agg and PS) get the benefits, but the
other backends which did not are still slow. Basically it is a problem
with a lot of redundant function call overhead. The backend_bases
renderer method _draw_markers discusses this a little bit (it is
underscore hidden).
Markers are not the issue here. These benchmarks were done with lines. There are markers for the ticks, of course, but the number of those are fixed. I agree it's function call overhead, but I believe it's in the overhead of PySequence_GetItem vs. array[index]. In both cases, the line is still getting drawn with a single Python -> C function call.
My guess is this difference will not be so pronounced on the trunk.
Actually, I'm getting surprising results there. Numbers are in fps.
Gtk GtkAgg
0.91.2, 1000 points 50 26
0.91.2, 10000 points 6 23
trunk, 1000 points 38 31
trunk, 10000 points 3 9
So, yes, the ratio between Gtk and GtkAgg on the trunk is not as pronounced. I'm a little disappointed by the timings on the trunk -- while one could say that Agg is a little better on the trunk with 1000 points, it doesn't scale nearly as well. That's certainly something to look into -- and I don't have any thoughts offhand. I would expect the trunk to do better since it doesn't perform a memory copy on the data with each call to draw_line/draw_path.
Cheers,
Mike
--
Michael Droettboom
Science Software Branch
Operations and Engineering Division
Space Telescope Science Institute
Operated by AURA for NASA
I have this "line simplification" stuff ported to the trunk. I've avoided the issues of bezier curves, compound polygons etc. for now -- the simplification will run only for simple series of line segments without fill. Chances are that if polygons or curves are being used, the number of vertices is relatively low anyway. I have yet to see a use case for a sequence of 100,000 bezier curves -- heck, it wasn't even possible in 0.91.2.
The results are quite good (see attached plots). GtkAgg scales approximately as well as 0.91.2 now, and Gtk is significantly better since it now takes advantage of line simplification (where it didn't before).
One caveat -- the benchmark I used is probably better than average for real data, since it uses a sampled sine wave, which is "smoother" than most real world data probably is, leaving lots of opportunities for line simplification. Time permitting, I might run the benchmark on random noise and see if there are significant differences. I would affect the performance to fall of faster in that case.
Cheers,
Mike
Michael Droettboom wrote:
···
Quick status update, and moving to matplotlib-devel, since I think this is no longer relevant to the OP --
The difference seems to be due to the simplification/clipping/decimation loop in the old draw_lines. It appears that even when you have a sine wave line plotted with 100,000 points, only 75 of them actually end up being sent to Agg. Valgrind's callgrind tells me that most of the time spent on the trunk when you have many line segments is spent stroking the line. So, clearly, drastically reducing the number of line segments should help immensely.
When I made the conversion from draw_lines to everything using draw_path, I had skipped over the simplification step because a) the problem is a little harder with general polycurves (since you can't stop in the middle of a curve) and b) I had assumed, with no evidence, that Agg would be doing some of this anyway.
So, I'm in the process of porting the big loop in draw_lines over to the trunk. It's complicated by curve problem and the desire to avoid a copy, of course, but it should be doable. There's probably a cross-over point at which the time spent simplifying the line becomes less than the time spent stroking the line. That will probably have to be arrived at by experimentation.
Cheers,
Mike
Michael Droettboom wrote:
John Hunter wrote:
On Jan 15, 2008 7:46 AM, Michael Droettboom <mdroe@...31...> wrote:
Ah -- just thought of something else.
If I adjust simple_plot_fps.py to have 100,000 data points rather than
1,000 I see something that starts to match with what you're seeing:
GtkAgg:
wallclock: 4.23297405243
user: 3.33
fps: 23.6240522057
Gtk:
wallclock: 15.0203828812
user: 14.92
fps: 6.65761990165
TkAgg:
wallclock: 4.8252530098
user: 4.67
fps: 20.7243018754
You can see that the Gtk time is starting to explode. If I go to
1,000,000 points, Gtk runs out of memory before the first plot, whereas
the other two continue to chug along at a reasonable pace.
From looking at the code, I suspect the crucial difference is that the
Gdk backend uses the Python sequence API (rather slow) to access the
data as it gets rendered, whereas GtkAgg uses the numpy array interface
which is essentially raw access to a C array.
This is not likely to be the culprit -- for drawing markers, the old
matplotlib API made a separate call to draw_polygon for every marker,
with a new gc each time. Many moons ago, we implemented draw_markers
as a renderer method to avoid this problem. For hundreds of thousands
of markers, we saw performance benefits of 25x to 100x. The backends
which implement draw_markers (Agg and PS) get the benefits, but the
other backends which did not are still slow. Basically it is a problem
with a lot of redundant function call overhead. The backend_bases
renderer method _draw_markers discusses this a little bit (it is
underscore hidden).
Markers are not the issue here. These benchmarks were done with lines. There are markers for the ticks, of course, but the number of those are fixed. I agree it's function call overhead, but I believe it's in the overhead of PySequence_GetItem vs. array[index]. In both cases, the line is still getting drawn with a single Python -> C function call.
My guess is this difference will not be so pronounced on the trunk.
Actually, I'm getting surprising results there. Numbers are in fps.
Gtk GtkAgg
0.91.2, 1000 points 50 26
0.91.2, 10000 points 6 23
trunk, 1000 points 38 31
trunk, 10000 points 3 9
So, yes, the ratio between Gtk and GtkAgg on the trunk is not as pronounced. I'm a little disappointed by the timings on the trunk -- while one could say that Agg is a little better on the trunk with 1000 points, it doesn't scale nearly as well. That's certainly something to look into -- and I don't have any thoughts offhand. I would expect the trunk to do better since it doesn't perform a memory copy on the data with each call to draw_line/draw_path.
Cheers,
Mike
--
Michael Droettboom
Science Software Branch
Operations and Engineering Division
Space Telescope Science Institute
Operated by AURA for NASA