Reinier Heeres wrote:
Hi Eric, all,
I've attached a new patch where I also allow two extra ways to define
color maps:
- by specifying (value, color) pairs, giving a linearly interpolated map.
- by specifying functions (gnuplot default functions are included)
I've added a few colormaps: afmhot, bwr, brg, gnuplot, gnuplot2,
ocean, rainbow, seismic, terrain
I refactored a few others: flag, prism, gist_gray, gist_heat,
gist_rainbow, gist_stern, gist_yarg. This saves about ~3000 lines...
(And the differences are very minor)
You can compare them with the old scales by running
examples/pylab_examples/show_colormaps.py both with and without the
attached patch.
What do you think? If it's ok, shall I push to trunk or v99?
Reinier,
First, this is a feature, not a bugfix, so it should go to the trunk.
Second, before it goes, I have some suggestions:
1) Avoid using the types module; it is too specific, too restrictive. e.g. instead of
+ if type(val) is types.FunctionType:
use
if callable(val):
instead of
+ if type(datad[cmapname]) is types.DictType:
you might use
cmapspec = datad[cmapname]
if 'red' in cmapspec:
....
else:
....
In each case, you may need to think about what kinds of arguments might be encountered, and what is the simplest and safest way to sort them out.
2) Related to the above, we really don't want to make distinctions among types of sequences unless there is no alternative--it is too confusing for users to remember that this has to be a tuple but that has to be a list, and the other thing has to be an ndarray. (Such distinctions in numpy's indexing rules make the indexing very flexible and powerful--but it is also very hard to remember exactly what those rules are. For numpy indexing, there was probably no alternative; for us there is.)
3) This statement from LinearSegmentedColormap.from_list
if len(colors[0]) == 2:
will fail with valid inputs, e.g. ['.2', 'r'] (recall that '.2' is a specification for gray on a 0-1 scale.)
What might work for parsing the colors argument is to take advantage of numpy's ability to figure out the dimensions of a possibly nested sequence:
colors = np.asarray(colors)
if colors.ndim == 2:
...
else: # assume it is 1-D, colors only
...
Turning arguments into ndarrays often simplifies the rest of the code, so long as one does not need to change the dimensions subsequently--lists are great for appending, deleting, etc. Sequence operations with ndarrays may be slower than using lists, tuples, and zip, but this doesn't matter at all in this part of the code.
4) This point could be considered now, or deferred: I originally tacked on the from_list method. It might make sense to deprecate it, and simply fold the logic into the __init__ method. One might want to keep the logic broken out into a method, and call that method to process the segmentdata argument. (The code in __init__ methods sometimes gets long and hard to follow; readability can be improved by separating parts out into methods, often private ones, and calling those in __init__.)
5) In _cm.py, if the maps you condensed are already identified in comments as to their sources, then you should add to those comments a note on how you modified them.
Thank you for your work on this.
Eric
···
Regards,
Reinier
On Thu, Aug 13, 2009 at 1:16 AM, Eric Firing<efiring@...229...> wrote:
Reinier Heeres wrote:
Hi all,
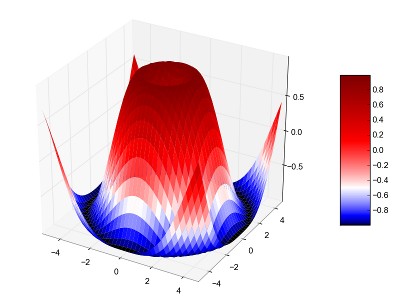
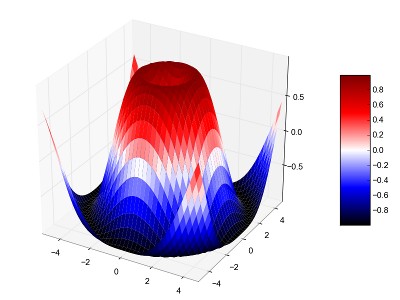
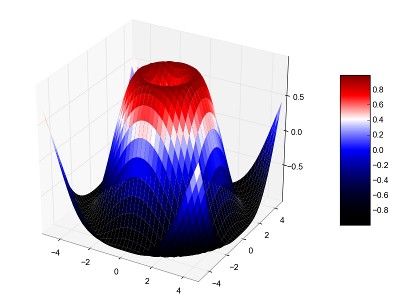
I would like to propose the attached patch to be able to use a gamma
value for color maps. This will make it simple to make your color
scale more 'sensitive' at the bottom or at the top, as can be seen in
the attached example. This could in principle also be solved by adding
a gamma normalizer, but I think that applying it to a color map is
quite coming practice, so in this case the preferred way.
Your patch looks reasonable to me.
I'd also like to add a few extra color maps (at least one plain
blue-white-red and one with darker shades at the high and low ends, as
Good.
in the attachment). I also remember a particular one ('terrain') in a
measurement program called 'Igor' that would be nice.
Is there any potential licensing problem? I hope not. I presume you would
copy the effect, not any particular set of numbers extracted from Igor.
Looking at _cm.py, I would guess that could be done a bit more
efficient than the current 5880 lines as well by just specifying a few
colors and using LinearSegmentedColormap.from_list(). Is it ok if I
try to refactor that?
You mean take the colormaps that have a huge number of color dictionary
entries in _cm.py, and subsample them down to something reasonable? Please
do! I always hated those blocks of numbers, but never enough to motivate me
to do something about them other than a little reformatting.
It sounds like you are talking about going farther than that, which might be
fine but might make things more complicated. As it is now, all the built-in
colormaps are associated with color dictionaries for direct use in
LinearSegmentedColormap. If you make two styles, one based on the
dictionaries (which allows discontinuities) and one based on from_list
(which does not), then you need to keep track of which is which. Is it
worth it? I am inclined to stick with the cdict approach.
It looks like an obvious addition would a function that takes a list of
breakpoints (starting with 0 and ending with 1) and a matching list of
colors and generates the corresponding cdict for continuous mapping.
Eric
Let me know what you think.
Cheers,